
Binomial distribution
Did you know...
This content from Wikipedia has been selected by SOS Children for suitability in schools around the world. A good way to help other children is by sponsoring a child
Probability mass function |
|
Cumulative distribution function Colors match the image above |
|
| Parameters | 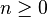 number of trials (integer) number of trials (integer)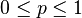 success probability (real) success probability (real) |
|---|---|
| Support | 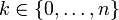 |
| PMF | 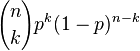 |
| CDF | 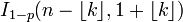 |
| Mean | 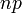 |
| Median | one of 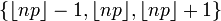 |
| Mode | 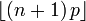 |
| Variance | 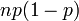 |
| Skewness | 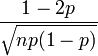 |
| Ex. kurtosis | 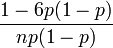 |
| Entropy | 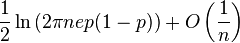 |
| MGF | 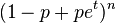 |
| CF | 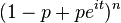 |
In probability theory and statistics, the binomial distribution is the discrete probability distribution of the number of successes in a sequence of n independent yes/no experiments, each of which yields success with probability p. Such a success/failure experiment is also called a Bernoulli experiment or Bernoulli trial. In fact, when n = 1, the binomial distribution is a Bernoulli distribution. The binomial distribution is the basis for the popular binomial test of statistical significance. A binomial distribution should not be confused with a bimodal distribution.
Examples
An elementary example is this: Roll a standard die ten times and count the number of sixes. The distribution of this random number is a binomial distribution with n = 10 and p = 1/6.
As another example, assume 5% of a very large population to be green-eyed. You pick 100 people randomly. The number of green-eyed people you pick is a random variable X which follows a binomial distribution with n = 100 and p = 0.05.
Specification
Probability mass function
In general, if the random variable K follows the binomial distribution with parameters n and p, we write K ~ B(n, p). The probability of getting exactly k successes in n trials is given by the probability mass function:
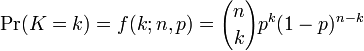
for k = 0, 1, 2, ..., n and where
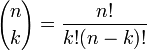
is the binomial coefficient (hence the name of the distribution) "n choose k" (also denoted C(n, k) or nCk). The formula can be understood as follows: we want k successes (pk) and n − k failures (1 − p)n − k. However, the k successes can occur anywhere among the n trials, and there are C(n, k) different ways of distributing k successes in a sequence of n trials.
In creating reference tables for binomial distribution probability, usually the table is filled in up to n/2 values. This is because for k > n/2, the probability can be calculated by its complement as
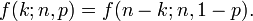
So, one must look to a different k and a different p (the binomial is not symmetrical in general).
Cumulative distribution function
The cumulative distribution function can be expressed in terms of the regularized incomplete beta function, as follows:
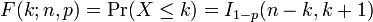
provided k is an integer and 0 ≤ k ≤ n. If x is not necessarily an integer or not necessarily positive, one can express it thus:
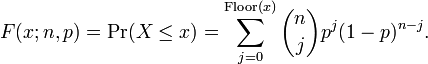
For k ≤ np, upper bounds for the lower tail of the distribution function can be derived. In particular, Hoeffding's inequality yields the bound
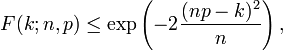
and Chernoff's inequality can be used to derive the bound
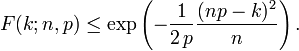
Mean, variance, and mode
If X ~ B(n, p) (that is, X is a binomially distributed random variable), then the expected value of X is
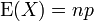
and the variance is
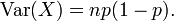
This fact is easily proven as follows. Suppose first that we have exactly one Bernoulli trial. We have two possible outcomes, 1 and 0, with the first having probability p and the second having probability 1 − p; the mean for this trial is given by μ = p. Using the definition of variance, we have
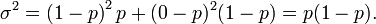
Now suppose that we want the variance for n such trials (i.e. for the general binomial distribution). Since the trials are independent, we may add the variances for each trial, giving
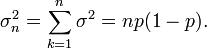
The mode of X is the greatest integer less than or equal to (n + 1)p; if m = (n + 1)p is an integer, then m − 1 and m are both modes.
Explicit derivations of mean and variance
We derive these quantities from first principles. Certain particular sums occur in these two derivations. We rearrange the sums and terms so that sums solely over complete binomial probability mass functions (pmf) arise, which are always unity
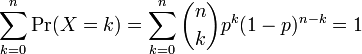
Mean
We apply the definition of the expected value of a discrete random variable to the binomial distribution
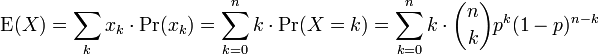
The first term of the series (with index k = 0) has value 0 since the first factor, k, is zero. It may thus be discarded, i.e. we can change the lower limit to: k = 1
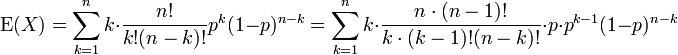
We've pulled factors of n and k out of the factorials, and one power of p has been split off. We are preparing to redefine the indices.
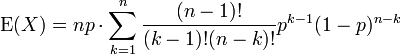
We rename m = n - 1 and s = k - 1. The value of the sum is not changed by this, but it now becomes readily recognizable
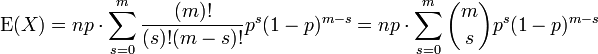
The ensuing sum is a sum over a complete binomial pmf (of one order lower than the initial sum, as it happens). Thus
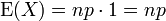
Variance
It can be shown that the variance is equal to (see: variance, 10. Computational formula for variance):
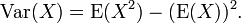
In using this formula we see that we now also need the expected value of X2, which is
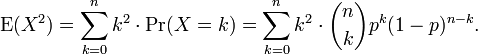
We can use our experience gained above in deriving the mean. We know how to process one factor of k. This gets us as far as
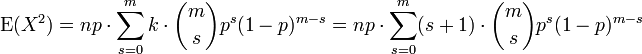
(again, with m = n - 1 and s = k - 1). We split the sum into two separate sums and we recognize each one
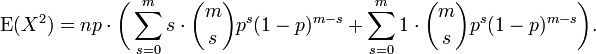
The first sum is identical in form to the one we calculated in the Mean (above). It sums to mp. The second sum is unity.
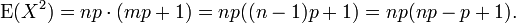
Using this result in the expression for the variance, along with the Mean (E(X) = np), we get
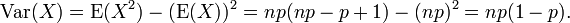
Relationship to other distributions
Sums of binomials
If X ~ B(n, p) and Y ~ B(m, p) are independent binomial variables, then X + Y is again a binomial variable; its distribution is
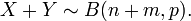
Normal approximation

If n is large enough, the skew of the distribution is not too great, and a suitable continuity correction is used, then an excellent approximation to B(n, p) is given by the normal distribution
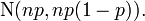
Various rules of thumb may be used to decide whether n is large enough. One rule is that both np and n(1 − p) must be greater than 5. However, the specific number varies from source to source, and depends on how good an approximation one wants; some sources give 10. Another commonly used rule holds that the above normal approximation is appropriate only if
![\mu \pm 3 \sigma = np \pm 3 \sqrt{np(1-p)} \in [0,n].](../../images/195/19591.png)
The following is an example of applying a continuity correction: Suppose one wishes to calculate Pr(X ≤ 8) for a binomial random variable X. If Y has a distribution given by the normal approximation, then Pr(X ≤ 8) is approximated by Pr(Y ≤ 8.5). The addition of 0.5 is the continuity correction; the uncorrected normal approximation gives considerably less accurate results.
This approximation is a huge time-saver (exact calculations with large n are very onerous); historically, it was the first use of the normal distribution, introduced in Abraham de Moivre's book The Doctrine of Chances in 1733. Nowadays, it can be seen as a consequence of the central limit theorem since B(n, p) is a sum of n independent, identically distributed 0-1 indicator variables.
For example, suppose you randomly sample n people out of a large population and ask them whether they agree with a certain statement. The proportion of people who agree will of course depend on the sample. If you sampled groups of n people repeatedly and truly randomly, the proportions would follow an approximate normal distribution with mean equal to the true proportion p of agreement in the population and with standard deviation σ = (p(1 − p)n)1/2. Large sample sizes n are good because the standard deviation, as a proportion of the expected value, gets smaller, which allows a more precise estimate of the unknown parameter p.
Poisson approximation
The binomial distribution converges towards the Poisson distribution as the number of trials goes to infinity while the product np remains fixed. Therefore the Poisson distribution with parameter λ = np can be used as an approximation to B(n, p) of the binomial distribution if n is sufficiently large and p is sufficiently small. According to two rules of thumb, this approximation is good if n ≥ 20 and p ≤ 0.05, or if n ≥ 100 and np ≤ 10.
Limits of binomial distributions
- As n approaches ∞ and p approaches 0 while np remains fixed at λ > 0 or at least np approaches λ > 0, then the Binomial(n, p) distribution approaches the Poisson distribution with expected value λ.
- As n approaches ∞ while p remains fixed, the distribution of
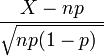
- approaches the normal distribution with expected value 0 and variance 1 (this is just a specific case of the Central Limit Theorem).